AWS Key Server
It’s the last day of 2010, and as an AWS fan there’s a lot to reflect on from the last year. There’s been several new SDKs, a couple of new services, more than twice as many consoles as there were this time last year, and so many major improvements to existing services that if I linked them all, every word in this post would be blue. It’s been really exciting, and nobody could have predicted half of this stuff in 2009.
With that in mind, I’m still going to go ahead and make a bold prediction: I believe, when all is said and done, that the most important release of 2011 will end up being the AWS Identity and Access Management (IAM) service, which is currently still in “Preview Beta”. I don’t know what else 2011 will bring, but I’d be surprised to see anything top this.
This needs justification, of course, since the beta has been proceeding with extremely little fanfare and very few of the AWS community have been talking about it. I think this is because it hasn’t been interpreted right yet; people (including Amazon’s own documentation[2]) still only refer to its ability to split up developers’ access to the account, so that testers can only access test instances, database maintainers can only access RDS operations, etc. This is all well and good, but by itself is not the reason I’m excited about IAM.
To explain, I have to bring up the pair of Mobile SDKs (Android and iOS) released earlier this month. They have an inherent critical flaw: credential management. If you want to write a mobile application that uses AWS services (but not on behalf of the user), you need to, at some point, have your credentials in memory on the device. You can try to obfuscate them, or minimize the amount of time it happens using various tricks like downloading them to SQLCipher-encrypted SQLite blocks, but at the end of the day, the request has to be signed on the device. This presents a problem because a skilled and determined attacker can run your APK in a simulator and read out your credentials no matter how well you’ve obfuscated them. You can try proxying all your requests through a server that does the signing, but that defeats the purpose of using AWS services in the first place — now you have another hop which can be a point of failure, latency, maintenance, which needs to be scaled, etc. I know this is a problem people are actually concerned about, because I’ve spent time answering questions about it in several places.
IAM solves this problem beautifully. It allows you to programatically create low-privileged user accounts on demand for every user of your mobile application, thereby resolving the problem of storing credentials by making the credentials worthless! The advantages are many:
- Prevents abusing the account in any way other than what could have been done from the application anyway.
- Allows you to control access through registration, paywalls, etc.
- Allows you to individually disable abusive accounts.
- Immediately provides fine-grained permissions control (like only allowing DeleteObject requests on S3 objects created by the same sub-account — the same functionality on a single account would require complicated bookkeeping somewhere else other than S3)
- Provides a crude form of analytics. You’ll at least have an upper bound on the number of unique users, and roughly how heavily each one is using it.
To demonstrate how neatly IAM works, I’ve created a proof-of-concept awskeyserver project on GitHub. It’s a Google App Engine service that creates on-demand IAM accounts through a RESTful interface. By default it gives them out to everyone, so hitting http://awskeyserver.appspot.com/create_user?group=Users will return something like AKIAIFY7K3N4Y6OE2DLQ:dGV6MHs3pMjRkT4RZmwnOZndOJG75FyOjpeQYVFA, which are the access credentials for an account in the Users group. In this case, the Users group has precisely no permissions, so it’s no big deal that I just posted those on my public blog (a few months ago that would’ve been a code-red disaster!). A mobile app can cache that and use it for the lifetime of the installation.
But that’s not all! If you’re noticing way too many requests for accounts, you can just edit permissions.py and add a CaptchaValidator() policy handler to the Users group. Once you do that, the previous request will instead return something like 03AHJ_VuueXyjZt-oM2Bf1K3c8rfsb_NHnjRQPLKDL0Vc1GhYs4LFmcuEYdBTfpGfYJbtRVwNL-OXeuAyApuHqrZ_J90i3qLJDHKepDFGIGTGQR8f1sRQpIchSDowHQHZczdbeLEdJPmR5Paiq_XjwzcJMMrZ4d1UHXQ, which is a reCAPTCHA challenge id. If you look that URL up in reCAPTCHA it’ll provide you with a captcha image, whose response has to be filled in (along with the challenge id) to the recaptcha_challenge_field and recaptcha_response_field query parameters to awskeyserver. Only then will it cough up the credentials, giving you a way to stem the flow. Captcha’s are one simple way of doing that, but I’ll be adding more context-aware validators to awskeyserver as time goes on.
To show how this works in practice, I’ve taken the sample AwsDemo application that comes with the AWS SDK for Android and modified it[1] to work without any local credentials at all. The modification only lives in one file, AwsDemo.java, which I’ve Gisted. It can handle both plain and captcha policies, and the returned credentials are limited by whatever permissions you set on the server side. In the example below, the group has the following policy file:
{
"Statement":[{
"Effect":"Allow",
"Action":["sdb:ListDomains"],
"Resource":"*"
}]
}
and awskeyserver has the policy:
policy = { "Users" : CaptchaValidator() }
So as you’ll see in the screenshots, listing domains works without a problem, but trying to access them results in an error:

Captcha-enabled key server challenge

Once the credentials are there, they're for listing SDB domains only

Any other operation results in an exception.
This sort of behavior was literally impossible to achieve safely before IAM, and now it’s an afternoon’s worth of work. That’s the reason I think IAM will be so huge — up until now, consumers of AWS have always had to hide behind a server, performing requests on the behalf of clients. Amazon always warned you never to give out your secret key (under any circumstances!) but people still did to services like s3fm or Ylastic, because there was simply no other way for them to work. IAM for the first time opens up the possibility for letting clients make their own requests, directly, without having to go against their own AWS accounts to do so. I imagine Dropbox‘s backend architecture would look quite different if it had been designed in a post-IAM world. They could have saved so much by pushing some of the logic their servers perform to the client side and letting it upload to S3 directly.
So yeah. I think 2011 will be the year of client-side AWS applications, and it will be IAM that allows this to happen. If I’m wrong, that means something even cooler comes out of there next year, and I can’t wait to see what it is.
[1]: This is not how I think production code should look like, by the way. It’s very proof-of-concept.
[2]: Well, with one exception. The bottom 10% of this.
Knuth’s “Why Pi” Talk at Stanford: Part 1

A few weeks ago I had another opportunity to meet a giant in my field: Donald Knuth was giving his annual Christmas Tree lecture at Stanford, where I happened to be near at the time. The most exciting part was probably right at the very beginning, when Knuth announced that, for the first (“and probably only”) time, he had finished two books on that same day: The Art of Computer Programming: Volume 4A, and Selected Papers on Fun and Games, with the pre-order links on Amazon going up the same day.
The topic of this year’s lecture was, according to the site:
Mathematicians have known for almost 300 years that the value of n! (the product of the first n positive integers) is approximately equal to
, where
is the ratio of the circumference of a circle to its diameter. That’s “Stirling’s approximation.” But it hasn’t been clear why there is any connection whatever between circles and factorials; the appearance of
I found the lecture originally hard to follow; although Knuth is now 74 years old and physically growing quite frail, his mind was still evidently much sharper than the audience’s; he was completely prepared for every question regarding extensions and corner cases of the material he was presenting. I considered the notes I took to be somewhat useless since I had spent so much time just trying to follow his reasoning. However, when the video became available, I had no excuse left, so I went through it again armed with a pen and the pause button, and I now have a set of notes somewhat worthy of posting here for anyone who missed it. Any errors or inconsistencies are almost definitely my fault and not his.
The notes themselves are after the jump.
Read the rest of this entry »
Some cool Zsh magic
If you’re a programmer, chances are you spend a lot of time deep inside some nested folder hierarchy. Oftentimes you want to jump back to some fixed point within that hierarchy, but you’re not exactly sure how many levels deep you are, so you just cd ../../..., using tab completion to guide you until you land where you want.
I find this annoying.
Ideally I would want to have some syntax like cd .../foo which would go back as many levels as needed until it finds foo (or /). If you’re using Bash, your best bet is to write a wrapper for cd which does exactly that. If you’re using Zsh (and you should be!) you can be much more clever. Add the following to your .zshrc file:
setopt extendedglob
function cdd() { builtin cd (../)##$1([1]) }
This is basically a high-powered alias that will use extended glob matching until it finds the shortest path of the form ../(../)*$1, where $1 is the first argument. The double-hashes ensure that at least one occurrence of (../) has to be there (otherwise it could match something in the current working directory). With that all set up, it’s a simple matter of:
$ pwd
/home/user/a/b/c/d/e/f
$ cdd c
$ pwd
/home/user/a/b/c
Good! But not quite good enough. This works for navigating with cd, but any other tool which uses paths would need their own command to pull off a similar trick. If you’re using Bash, this is really the end of the line for you. Zsh users, however, can man zshall, grep for zsh_directory_name, and get a big smile on their face. zsh_directory_name is a shell function that basically allows you to process any path entered in the form ~[path] in the substitution phase. With this facility, we can add the following to .zshrc:
zsh_directory_name () { [[ $1 != n ]] && return 1; reply=( (../)##$2([1]) ) }
The ‘n‘ string checks whether zsh_directory_name is being called to do directory expansion (n) or directory naming (d). If so, the reply array is basically doing the same trick cdd does on $2.
Once we have that, we can operate on any token:
$ pwd
/home/user/a/b/c/d/e/f
$ ls ~[a]
b
$ mkdir ~[a]/g
$ ls ~[a]
b g
Awesome!
Next Steps in GAE-AWS SDK
I’ve been getting lots of great feedback on the GAE port of the AWS SDK for Java that I released a few months back as part of a school project I was working on. As I’d hoped, it’s grown way beyond that, and there’s lots of people that have let me know they’re making use of it with GAE. For my part, I’ve been keeping it up-to-date and working within a few days of each new AWS SDK for Java release — all 14 of them!
Unfortunately (as those people are well aware) it’s far from complete, and is actually quite buggy. This is not the AWS SDK’s fault, but rather due to the hacks I needed to put in place to get around GAE’s restrictions and bugs. Regardless of where the blame lies, however, the point is still that it has been holding back the improvements people have been asking for (chief among of them being support for S3).
Today I’m making a “new release” available. Unfortunately it doesn’t include S3 support, which still requires a large amount of rethinking, but it does include a major piece of functionality: suites of integration tests. Setting up test cases for the SDK on App Engine as well as the local Jetty server is a painful and time-consuming process (and don’t assume that those two things behave the same — they don’t at all, with respect to GAE-AWS). It’s been the main thing holding back rapid development. But now you can visit http://gae-aws-sdk-test.appspot.com, enter your AWS credentials, choose some service test suites, and see the current development version of the SDK running on App Engine!

As you can see, they don't all pass yet...
The exact same thing works locally (though you may be surprised to see very different results!) If you don’t feel comfortable sending your AWS credentials to my GAE app, feel free to download the code and run your own instance.
Google has really instilled some testing discipline in me, so I feel much more comfortable now ripping out the innards of the S3 client in order to make it GAE-ready and satisfy some of the requests I’ve been getting. Until then, grab the GAE-AWS SDK for the other 15 or so services and play around with it. Now that there’s a free tier for AWS to go along with free Google App Engine quota, the barrier to entry for cloud computing is at an historic low.
Enjoy!
S3FS
![]() A short while ago, I took a renewed interest in Randy Rizun’s S3FS project (which had mostly been stagnating) and cloned it to GitHub. It’s basically a FUSE module backed by an S3 bucket. It’s often used on EC2 instances to provide a shared persistent store (which means no EBS); nothing too fancy, but it nicely combines several of my technical interests. I began cleaning it up to prepare it for packaging to Debian and Gentoo, which involved moving it to Autotools, when I was contacted by another developer who had simultaneously decided to rehabilitate the project as well. He had taken the extra effort of contacting Randy about getting us commit access to the original project, which was swiftly granted, so now those changes have been rolled in. Dan also fixed up a lot of outstanding issues, and I’ve started refactoring the old code. The renewed activity must have caught users’ attention as well, because we’ve started getting patches, such as this one to cache read-only files. So it looks like there’s bright things in store for S3FS! Some of the things on my road map (and I don’t speak for Dan here) are:
A short while ago, I took a renewed interest in Randy Rizun’s S3FS project (which had mostly been stagnating) and cloned it to GitHub. It’s basically a FUSE module backed by an S3 bucket. It’s often used on EC2 instances to provide a shared persistent store (which means no EBS); nothing too fancy, but it nicely combines several of my technical interests. I began cleaning it up to prepare it for packaging to Debian and Gentoo, which involved moving it to Autotools, when I was contacted by another developer who had simultaneously decided to rehabilitate the project as well. He had taken the extra effort of contacting Randy about getting us commit access to the original project, which was swiftly granted, so now those changes have been rolled in. Dan also fixed up a lot of outstanding issues, and I’ve started refactoring the old code. The renewed activity must have caught users’ attention as well, because we’ve started getting patches, such as this one to cache read-only files. So it looks like there’s bright things in store for S3FS! Some of the things on my road map (and I don’t speak for Dan here) are:
- .debs and .ebuilds for inclusion into (at least) the distributions I’m familiar with, and which are commonly used with EC2.
- Port to MacFUSE.
- GVFS/KIO wrappers for proper integration into Gnome/KDE. I haven’t done much research into this one yet, so I’m not sure how much of an undertaking this will turn out to be.
- Intelligent caching.
- Some rudimentary mapping of ACLs to Unix permissions.
- General code clean-up and refactoring.
The Knight Metric
Here’s a problem I’ve been thinking about. I’m curious if anybody has any ideas about it; I have reasons to believe it might be very hard (in the theoretical sense) but I haven’t given it much time yet.
Consider a (possibly infinite) two-dimensional integer grid
, with some finite subset of its cells colored black. We consider two cells
to be connected if
; that is, if the cells are a knight’s move apart. Write a function that computes the least number of additional cells that would need to be colored black in order to ensure that there exists a connected path between any two black cells.
The trickiness comes from the fact that adding a black square can either increase or decrease the total number (it’s not hard to come up with examples of either possibility), so the problem resists simplification. I have no idea if this can be computed in polynomial time or space. I thought of it in the context of geometric constructions, for which computability results are notoriously difficult, but it smells like this can be solved in purely graph-theoretic terms. There is actually a closed formula for the “knight’s distance” between two points, though it is a bit complicated:
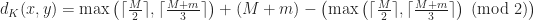
where
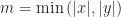
Except that it doesn’t work. It’s minimizing the wrong thing: distance, instead of the minimum number of squares. Consider the following configuration:

Figure A
It’s easy to see that there’s (two) ways to solve this problem by adding just a single square (either x or y). Therefore, the answer to our problem is 1. However, the above approach would instead notice that it could make all the distances be less than or equal to 2 by adding x and y and z, while adding just x would make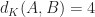
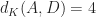
Thus the problem has some non-local properties that I don’t really know how to translate into graph-theoretic terms, unless I just consider all paths within a certain ball whose size is linear in the diameter of the graph, but that would be exponential.
If anyone has any clever ideas, I’d be interested in hearing about it.
Java puzzler: Generic type inference
Here’s an issue I ran into while hacking a type system to work with some very inflexible generated code; I’ve distilled the strangeness into the simplest form I could.
Suppose you have a simple type hierarchy:
public class A { }
public class B extends A { }
public class C extends A { }
Then, it turns out that the following code works just fine:
List<Class<? extends A>> list = ImmutableList.of(B.class, C.class);
Surprisingly, however, the following code fails to compile(!):
List<Class<? extends A>> list = ImmutableList.of(B.class);
with the error
incompatible types
found : com.google.common.collect.ImmutableList<java.lang.class<B>>
required: java.util.List<java.lang.class<? extends A>>
List<Class<? extends A>> list = ImmutableList.of(
...
That’s right; adding the parameter makes this typesafe! (Note that my example uses ImmutableLists from the Google Common Collections, but this is actually happening because of Java’s type inference mechanism, not anything related to that particular class). Of course, it’s easy to work around it, but the interesting thing is what can be learned about Java by understanding the problem here.
I’ll post a “solution” in a few days, in case anyone wants to give it a shot.
Kindle Goban
![]() One of the things I’ve been working on in my copious free time has been a pair of Kindle applications that are near to my heart. By this time it’s no surprise to anyone that Amazon has released a Kindle Development Kit which allows a couple of beta developers to write native applications for the device; it’s not entirely surprising that this was announced two weeks before the anticipated iPad announcement. What is surprising is that, around six months later, there is still no sign of app distribution actually beginning, nor have they given any of the beta developers even an inkling of when (or if) that will be happening.
One of the things I’ve been working on in my copious free time has been a pair of Kindle applications that are near to my heart. By this time it’s no surprise to anyone that Amazon has released a Kindle Development Kit which allows a couple of beta developers to write native applications for the device; it’s not entirely surprising that this was announced two weeks before the anticipated iPad announcement. What is surprising is that, around six months later, there is still no sign of app distribution actually beginning, nor have they given any of the beta developers even an inkling of when (or if) that will be happening.
Personal gripes aside, the technology itself is pretty interesting. (I’m technically under an NDA, so I’ll avoid saying anything not obvious from the publicly-available Javadocs) The first thing that is clearly being emphasized, right from the name — it’s not “Kindle Applications” but “Kindle Active Content” that we’re developing, after all — is that the KDK (or, indeed, the Kindle) is not well-suited to traditional mobile applications (by which everyone means, iOS applications). First of all, the screen’s refresh rate is literally measured in seconds, and the amount of processing time it takes to do something like load a bunch of images can actually safely be measured in tens of seconds. Secondly, (as-is-publicly-stated-on-their-webpage-so-please-don’t-sue-me-Amazon), because the wireless plan is all paid for by Amazon, they’re very stingy with the amount of data your app can use, there’s no way to programatically access your current total usage, overflow charges are actually charged to the developer, and the lack of a Wi-Fi option, the foregone conclusion is that most developers will not make more than nominal use of the networking component of the Kindle.
So what does that leave us with? Surprisingly, my answer is still “quite a lot.” Because Amazon is right, the Kindle is not an iPad no matter how much the Apple blogs compare them, and the kinds of “apps” you see on the latter does not translate into good “Active Content” for the former. Good Kindle content is exactly what their marketing name sounds like — a way of leveraging the advantage of an electronic device over a paper book, rather than constantly trying to imitate every physical aspect of it. Of course, a lot of people’s imagination when they hear that goes as far as “embedded video” or something (which can be very well-done, of course), but I think there’s a lot more to it than that; people have just become so used to the static nature of books today, that seeing their future as more than just a webpage is really quite a mental leap. Now, when it comes to most types of books, like fiction, that probably is about as far as we can stretch the metaphor. But for other “technical-knowledge” kinds of books, we can do much better.
For example, I’m really into Chess and Go. It probably comes as a surprise to most people not in that “scene” that there’s actually a vast technical literature behind each of these two subjects. There are (literally) thousands of English-language Chess books alone, and dozens more being published every year; and I’m not just talking about “Mickey-Mouse Teaches Chess” types of things either. These consist of important new research in opening ideas, widely read by virtually all competitive players, and cuttingly relevant. It’s not unusual for high-level chess players to describe a book printed in 2005 as “very good, but too outdated to be useful.” My point here is just that I’m not picking a purely niche, toy example to start off. Now, if you’ve ever looked at a non-beginner-oriented Chess book, it often looks something like this:

Despite what it looks like, this is actually NOT a Perl script! Humans read this!
Okay, so two problems here. First of all, in spite of the superhuman impression many chess players would like you to have of them, it’s not easy for anyone to visualize the lines shown above in the kind of way that would be conducive to learning. Even for super-grandmasters, all you have to do is look at games from blindfold tournaments like Melody-Amber to confirm that thinking of chess in purely logical, textual terms is a handicap for anyone. Most books will print diagrams every so often, but they’re limited by space so these are typically only printed in whichever positions the author deems critical; it is left up to the players to visualize the lines in between. So in order to really make use of this book, you’d need to have a physical board or a chess program available to transcribe the moves onto — at which point, what’s the point of even studying this in a book? ChessBase probably has a nice DVD about the French Defence you can watch instead, which would surely be a much more pleasant experience. Second of all, chess players born after the 1970’s would have a hard time understanding the notation in this old book anyway, because it uses “descriptive notation” rather than the modern “algebraic notation” that new players are brought up on. That’s right: chess has two mutually exclusive but equivalent languages for the same market — and the vast majority of books are only ever printed in one of them. And yet people put up with this because there is something useful and exciting being written here, it’s just hidden behind this wall of notation. It’s the price you pay to remain a competitive player.
Solving problems like this, I think, is where the Kindle can bring an actual measurable advantage over the paperbacks to which it’s constantly being unfavourably compared. It should be striving for more than simple duplication. On a Kindle, the software can convert algebraic notation to descriptive notation to match the reader’s preference. It can place diagrams wherever and as often as the reader wants — and make them interactive, with the user scrolling through moves and trying sidelines not covered by the text. The author can choose as many real games to illustrate a point as he wants without worrying about taking up too many pages or boring they user, because they can all be collapsed or expanded on demand. This, also, is where the Kindle differentiates itself from the iPad. There’s over 20 chess-playing apps in the Apple App Store — but there can be a chess-publishing app on the Kindle store, and any serious player can tell you which one they’d rather have available on a long airplane ride. And although chess and Go are my hobby-horses that I perennially focus my examples on, it doesn’t take much to see that the same principle applies to other technical topics in which text is not necessarily the most natural way to express ideas — engineering, programming, mathematics … the sky’s the limit.
So this is why I’m excited about the KDK in spite of its shortcomings. This is what the KDK eventually could become; it’s not yet, because unfortunately the applications are still stand-alone at this point and not “plug-in-able” to items in the library. The place where Active Content belongs, in my opinion, is as an extension to the MOBI format — or an entirely new format which Amazon almost uniquely is in the position to define and propagate. But I’ll take what I can get. I’ve started implementing a publishing platform for Go (as a proof-of-concept) which allows a lot of the things I’ve described. I’ve also got a branch running for Chess, but that one’s not testable on device yet because of technical issues (missing Unicode glyphs for the chess pieces). You can find both of them on GitHub at KindleChess and KindleGoban respectively, but it’s really kind of moot for now because nobody except other developers can actually run Kindle applications yet. To whet your appetite, however, and possibly as one of the first examples of Kindle apps in the wild, here’s what it looks like:

Anyone recognize the match?
At the moment, it can take any SGF and generate a book-like thing out of it, with markup, comments, and variations. Of course, this falls short of the vision I outlined above, where the visual widgets plug into the flow of otherwise normal text — but that will probably have to wait until the KDK becomes more powerful and allows code to be embedded into regular library items (or even just let applications provide library items… I’ll write a whole parser if I have to).
AWS Automator Actions
![]() Automator has always been one of those OS X features that I feel never gets enough attention, except when it’s in one of those “comparison” articles that always seems to mention it because it’s so unique and novel; but once the initial wave of First Look and Sneak Peek and Oh-my-God-I-can’t-believe-we’re-the-only-magazine-covering-this articles dies out, you never hear about it again, even though there is, in fact, a fairly active community of users and developers around it.
Automator has always been one of those OS X features that I feel never gets enough attention, except when it’s in one of those “comparison” articles that always seems to mention it because it’s so unique and novel; but once the initial wave of First Look and Sneak Peek and Oh-my-God-I-can’t-believe-we’re-the-only-magazine-covering-this articles dies out, you never hear about it again, even though there is, in fact, a fairly active community of users and developers around it.
In fact, Snow Leopard added, with little fanfare, many useful features to Automator 2.1; the most interesting among these, I think, is the ability to run shell scripts in anything that emulates a shell, including Python (and Ruby, and Perl). Now, of course, there had been hand-made solutions to this before (Automator’s extendability being another not-often-touted feature) but having it built-in just makes distribution and adoption easier. Apple’s version, as well, seems a bit simpler since it doesn’t use the PyObjC bridge to pass around the full AppleScript event descriptor, instead just passing the text in through argv or stdin. Of course this means it’s strictly less powerful than Johnathan’s version, but let’s face it — if you really need to be using this bridge, it’s probably overkill for Automator anyway. Besides, it’s almost always possible to save whatever kind of data you need (an image, most commonly) to a temporary file in /tmp and just pass the path to Python, anyway.
Anyway, although I’m not a heavy Automator user by any stretch (most people who can write proper scripts aren’t, after all), I’m a big proponent of it as an idea, particularly in the way it easily allows non-technical users to automate away a lot of the tedium that comprises the majority of many people’s computing experience. And even if you can script something in the traditional way, Automator is often the easiest way to Cocoa-ize a simple script so that it can grab selections from Finder, insert itself into the Services menu, etc. Yesterday I wanted to do something to this effect — an easy way to upload directory structures to S3, sort of as an impulse click rather than going through the trouble of opening up a client, etc., since it’s an operation Rachel and I perform manually all the time. It was delightfully simple to use Automator to pass in Finder selections to a simple Python script that did the heavy lifting. Without Automator, the boilerplate would have been many times longer than the remarkably simple script itself:
import os
import sys
AWS_ACCESS_KEY = sys.argv[1]
AWS_SECRET_KEY = sys.argv[2]
bucket_name = sys.argv[3].lower()
return_url = ""
files = []
for f in sys.argv[4:]:
files.append(f)
sys.path.insert(0, '/sw/lib/python2.6/site-packages')
import boto
import boto.s3 as s3
from boto.s3.key import Key
def recursively_upload(f, prefix = ''):
if (os.path.isdir(f)):
for ff in os.listdir(f):
recursively_upload('/'.join([f, ff]), ''.join([prefix, f[f.rindex('/')+1:], '/']))
else:
global return_url
k = Key(bucket)
k.key = ''.join([prefix, f[f.rindex('/')+1:]])
k.set_contents_from_filename(f, policy='public-read')
return_url = "".join(["http://", bucket_name, ".s3.amazonaws.com/", k.key])
conn = boto.connect_s3(AWS_ACCESS_KEY, AWS_SECRET_KEY)
bucket = conn.create_bucket(bucket_name, location=s3.connection.Location.DEFAULT)
for f in files:
recursively_upload(f)
print return_url
The only gotcha is the sys.path.insert(0, '/sw/lib/python2.6/site-packages') line, which is there because the sandboxed shell that Automator spawns has no access to PYTHONPATH or anything; you have to programatically load third-party modules if you want them. The module, in this case, is boto, an AWS library for Python; you’ll have to change that line to the appropriate path for your installation if you want to run it (or, if you installed boto-py26 through Fink, don’t do anything). When you combine the above script with the following Automator workflow:

You know what that is? That's dozens of lines of boring Python that didn't get written!

Equally happy with flat files and directories
Simply saving that in Automator automatically gives you what you see on the right here. Also, I took both these screenshots in just a few seconds with another Automator script that took just a few minutes to write that automatically takes a screenshot, uploads it to S3, and puts the link into your clipboard. Both of these scripts and workflows are available from my Codebook GitHub repository.
Of course, I think it would be infinitely better to have native Automator actions for common AWS operations, but that would require a solid Objective-C library first, of which there aren’t any yet 😦
Introducing the GAE-AWS SDK for Java
![]() I’m making what I hope will be a useful release today — a version of the Amazon Web Services SDK for Java that will run from inside of Google App Engine. This wouldn’t work if you simply included the JAR that AWS provides directly into GAE’s WAR, because GAE’s security model doesn’t allow the Apache Commons HTTP Client to create the sockets and low-level networking primitives it requires to establish an HTTP connection; instead, Google requires you to make all connections through its URLFetch utility. This version of the SDK does exactly that, swapping out the Apache HTTP Connection Manager for one that returns URLFetchHttpConnections.
I’m making what I hope will be a useful release today — a version of the Amazon Web Services SDK for Java that will run from inside of Google App Engine. This wouldn’t work if you simply included the JAR that AWS provides directly into GAE’s WAR, because GAE’s security model doesn’t allow the Apache Commons HTTP Client to create the sockets and low-level networking primitives it requires to establish an HTTP connection; instead, Google requires you to make all connections through its URLFetch utility. This version of the SDK does exactly that, swapping out the Apache HTTP Connection Manager for one that returns URLFetchHttpConnections.
With it, you can make use of the multitude of powerful AWS services (excepting S3, which requires more work before it will integrate properly) from within Google App Engine, making both of these tools significantly more useful. In fact, AWS seems to nicely complement several of Google App Engine’s deficiencies; for example, my original motivation for creating this was to be able to make SimpleDB requests from GAE for a school project I’m working on.
Using it is very simple — just download the full package from its GitHub page, and add all of the JAR files in the package (including the third-party/ directory) to Google App Engine’s war/WEB-INF/lib/ directory, and add them to your build path in Eclipse. Then just use the SDK in the usual fashion! For example, the following lines of code:
AmazonSimpleDB sdb = new AmazonSimpleDBClient(new PropertiesCredentials("AWSCredentials.properties"));
sdb.setEndpoint("http://sdb.amazonaws.com");
String serverInfo = getServletContext().getServerInfo();
String userAgent = getThreadLocalRequest().getHeader("User-Agent");
return "Hello, " + input + "!<br><br>I am running " + serverInfo
+ ".<br><br>It looks like you are using:<br>" + userAgent
+ ".<br><br>You have " + sdb.listDomains().getDomainNames().size() + " SDB domains.";
turns the usual GWT welcome page into this:

Notice the last line there!
I intend to merge in all upstream changes from the real AWS SDK for Java, of which this is simply a GitHub fork. Please post any issues or questions you have in the GitHub page!
